{
"metadata": {
"name": "recitation11"
},
"nbformat": 3,
"nbformat_minor": 0,
"worksheets": [
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# CS1001.py\n",
"\n",
"## Extended Introduction to Computer Science with Python, Tel-Aviv University, Spring 2013\n",
"\n",
"# Recitation 11 - 23-27.5.2013\n",
"\n",
"## Last update: 28.5.2013"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
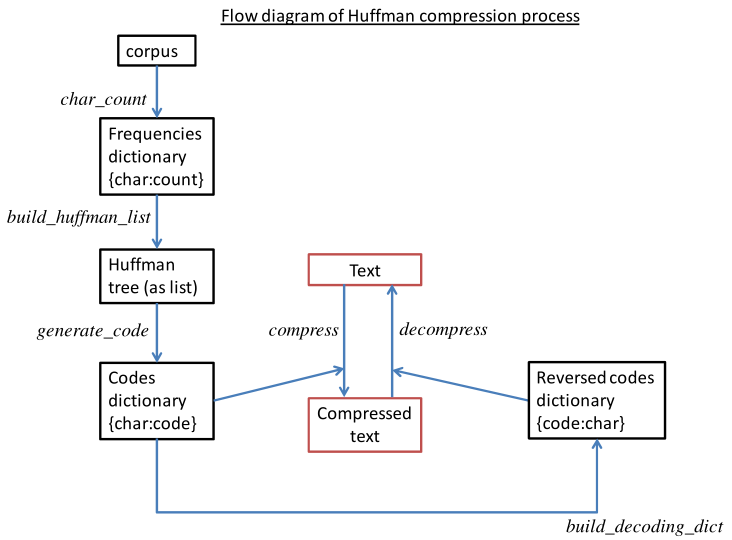
"# Huffman codes\n",
"\n",
"Unicode and [ASCII](http://www.asciitable.com/) code map characters to bits, but all characters (letters, numbers, punctuation marks) map to the same number of bits (7 for ASCII).\n",
"\n",
"The **Huffman code** is a *variable length code*. The code length (in bits) for each datum (data point) is proportional to its frequency in the data. This is effectively a *loss-less compression*. The frequencies are calculated from a **corpus** - a big representative data set. \n",
"\n",
"To preserve the reversability of the code (one-to-one) we use **prefix free** codes - no code is a prefix of another code, i.e. if 0110 is a code, then there is no other code theat begins with 0110.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We start with a simple code for creating a histogram of the data:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def char_count(text):\n",
" histogram = {}\n",
" for ch in text:\n",
" histogram[ch] = histogram.get(ch, 0) + 1\n",
" return histogram"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 1
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"letter_count = char_count(\"live and let live\")\n",
"letter_count"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 2,
"text": [
"{' ': 3, 'a': 1, 'd': 1, 'e': 3, 'i': 2, 'l': 3, 'n': 1, 't': 1, 'v': 2}"
]
}
],
"prompt_number": 2
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next we need to build the Huffman tree."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def by_value(tup):\n",
" return tup[1]\n",
"\n",
"def build_huffman_tree(letter_count):\n",
" \"\"\" recieves dictionary with char:count entries\n",
" generates a list of letters representing the binary Huffman encoding tree\"\"\"\n",
" queue = list(letter_count.items())\n",
" while len(queue) >= 2:\n",
" queue.sort(key=by_value) # sort by the count\n",
" # combine two least frequent elements\n",
" elem1, freq1 = queue.pop(0)\n",
" elem2, freq2 = queue.pop(0) \n",
" elems = (elem1, elem2)\n",
" freqs = freq1 + freq2\n",
" queue.append((elems,freqs))\n",
" return queue[0][0]"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 3
},
{
"cell_type": "code",
"collapsed": false,
"input": [
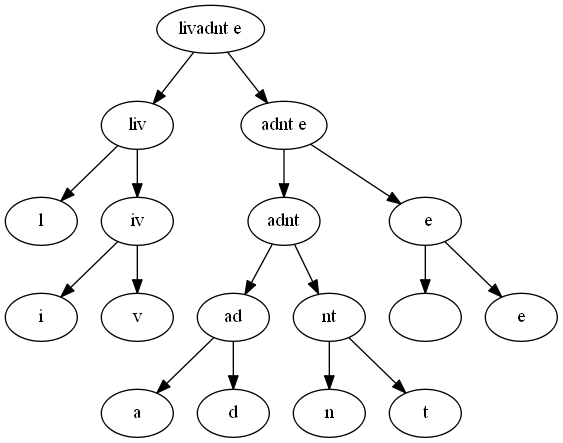
"tree = build_huffman_tree(letter_count)\n",
"tree"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 4,
"text": [
"(('l', ('i', 'v')), ((('a', 'd'), ('n', 't')), (' ', 'e')))"
]
}
],
"prompt_number": 4
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def build_codebook(huff_tree, prefix=''):\n",
" \"\"\" receives a Huffman tree with embedded encoding and a prefix of encodings.\n",
" returns a dictionary where characters are keys and associated binary strings are values.\"\"\"\n",
" if isinstance(huff_tree, str): # a leaf\n",
" return {huff_tree: prefix}\n",
" else:\n",
" left, right = huff_tree\n",
" codebook = {}\n",
" codebook.update( build_codebook(left, prefix + '0'))\n",
" codebook.update( build_codebook(right, prefix + '1'))\n",
" return codebook"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 5
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"codebook = build_codebook(tree)\n",
"for ch,freq in sorted(letter_count.items(), key=by_value, reverse=True):\n",
" print(ch, freq, codebook[ch])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
" 3 110\n",
"e 3 111\n",
"l 3 00\n",
"i 2 010\n",
"v 2 011\n",
"a 1 1000\n",
"d 1 1001\n",
"n 1 1010\n",
"t 1 1011\n"
]
}
],
"prompt_number": 6
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def compress(text, codebook):\n",
" ''' compress text using codebook dictionary '''\n",
" return ''.join(codebook[ch] for ch in text if ord(ch) <= 128)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 7
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"ch,ord(ch),'{:08b}'.format(ord(ch))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 13,
"text": [
"('t', 116, '01110100')"
]
}
],
"prompt_number": 13
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"bits_ascii = ''.join(['{:07b}'.format(ord(ch)) for ch in \"live and let live\" if ord(ch) <= 128])\n",
"huff_bits = compress(\"live and let live\", codebook)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 21
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"print(len(bits_ascii),bits_ascii)\n",
"print(len(huff_bits),huff_bits)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"119 11011001101001111011011001010100000110000111011101100100010000011011001100101111010001000001101100110100111101101100101\n",
"52 0001001111111010001010100111000111101111000010011111\n"
]
}
],
"prompt_number": 22
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def build_decoding_dict(codebook):\n",
" \"\"\"build the \"reverse\" of encoding dictionary\"\"\"\n",
" return {v:k for k,v in codebook.items()}"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 12
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"decodebook = build_decoding_dict(codebook)\n",
"decodebook"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 13,
"text": [
"{'00': 'l',\n",
" '010': 'i',\n",
" '011': 'v',\n",
" '1000': 'a',\n",
" '1001': 'd',\n",
" '1010': 'n',\n",
" '1011': 't',\n",
" '110': ' ',\n",
" '111': 'e'}"
]
}
],
"prompt_number": 13
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def decompress(bits, decodebook):\n",
" prefix = ''\n",
" result = []\n",
" for bit in bits:\n",
" prefix += bit\n",
" if prefix not in decodebook:\n",
" continue\n",
" result.append(decodebook[prefix])\n",
" prefix = ''\n",
" assert prefix == '' # must finish last codeword\n",
" return ''.join(result) # converts list of chars to a string"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 14
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"decompress(huff_bits, decodebook)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 15,
"text": [
"'live and let live'"
]
}
],
"prompt_number": 15
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Examples"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def huffman_code(corpus):\n",
" counts = char_count(corpus)\n",
" tree = build_huffman_tree(counts)\n",
" return build_codebook(tree)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 16
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There is only one way to create the codebook for this corpus:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"huffman_code('aaabbc')"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 17,
"text": [
"{'a': '0', 'b': '11', 'c': '10'}"
]
}
],
"prompt_number": 17
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are different ways to create a codebook for this corpus - `b` and `c` are interchangeable:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"huffman_code('aaabbcc')"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 18,
"text": [
"{'a': '0', 'b': '11', 'c': '10'}"
]
}
],
"prompt_number": 18
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here the frequency of all characters is equal, so the code is actually a fixed length code - most characters "
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"codebook = huffman_code('qwertuioplkjhgfdsazxcvbnm')\n",
"codebook"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 19,
"text": [
"{'a': '01110',\n",
" 'b': '10000',\n",
" 'c': '01111',\n",
" 'd': '10010',\n",
" 'e': '10001',\n",
" 'f': '10100',\n",
" 'g': '10011',\n",
" 'h': '10110',\n",
" 'i': '10101',\n",
" 'j': '11000',\n",
" 'k': '10111',\n",
" 'l': '11010',\n",
" 'm': '11001',\n",
" 'n': '11100',\n",
" 'o': '11011',\n",
" 'p': '11110',\n",
" 'q': '11101',\n",
" 'r': '0000',\n",
" 's': '11111',\n",
" 't': '0010',\n",
" 'u': '0001',\n",
" 'v': '0100',\n",
" 'w': '0011',\n",
" 'x': '0101',\n",
" 'z': '0110'}"
]
}
],
"prompt_number": 19
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Average length of 4.72, most codes are of length 5:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"mean([len(v) for v in codebook.values()])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 20,
"text": [
"4.7199999999999998"
]
}
],
"prompt_number": 20
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the next corpus every letter appears a different number of times:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"corpus = ''.join([ch*(i+1) for i,ch in enumerate('qwertuioplkjhgfdsazxcvbnm') ])\n",
"corpus"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 21,
"text": [
"'qwweeerrrrtttttuuuuuuiiiiiiioooooooopppppppppllllllllllkkkkkkkkkkkjjjjjjjjjjjjhhhhhhhhhhhhhggggggggggggggfffffffffffffffddddddddddddddddsssssssssssssssssaaaaaaaaaaaaaaaaaazzzzzzzzzzzzzzzzzzzxxxxxxxxxxxxxxxxxxxxcccccccccccccccccccccvvvvvvvvvvvvvvvvvvvvvvbbbbbbbbbbbbbbbbbbbbbbbnnnnnnnnnnnnnnnnnnnnnnnnmmmmmmmmmmmmmmmmmmmmmmmmm'"
]
}
],
"prompt_number": 21
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"huffman_code(corpus)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 22,
"text": [
"{'a': '0100',\n",
" 'b': '1011',\n",
" 'c': '1000',\n",
" 'd': '0010',\n",
" 'e': '1101110',\n",
" 'f': '0000',\n",
" 'g': '11111',\n",
" 'h': '11110',\n",
" 'i': '00010',\n",
" 'j': '11010',\n",
" 'k': '10011',\n",
" 'l': '10010',\n",
" 'm': '1110',\n",
" 'n': '1100',\n",
" 'o': '00011',\n",
" 'p': '01010',\n",
" 'q': '11011110',\n",
" 'r': '010110',\n",
" 's': '0011',\n",
" 't': '010111',\n",
" 'u': '110110',\n",
" 'v': '1010',\n",
" 'w': '11011111',\n",
" 'x': '0111',\n",
" 'z': '0110'}"
]
}
],
"prompt_number": 22
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"What do we do if some characters in the text did not appear in the corpus?\n",
"\n",
"- We can add them to the corpus - not very reasonable for large text\n",
"- We can add all characters to the corpus with a small initial frequency:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"print(''.join([chr(c) for c in range(128)]))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\u0000\u0001\u0002\u0003\u0004\u0005\u0006\u0007\b\t\n",
"\u000b",
"\f",
"\r",
"\u000e\u000f\u0010\u0011\u0012\u0013\u0014\u0015\u0016\u0017\u0018\u0019\u001a\u001b\u001c",
"\u001d",
"\u001e",
"\u001f !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\u007f\n"
]
}
],
"prompt_number": 23
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Compression ratio\n",
"\n",
"This is a measure of how much space is saved by using the Huffman code to compress the text:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def compression_ratio(text, corpus):\n",
" codebook = huffman_code(corpus)\n",
" len_compress = len(compress(text, codebook))\n",
" len_ascii = len(text) * 7\n",
" return len_compress / len_ascii"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 24
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets see how the language of the corpus affects the compression ratio:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"from urllib.request import urlopen\n",
"with urlopen(\"http://www.gutenberg.org/cache/epub/42745/pg42745.txt\") as f:\n",
" gauss = f.read().decode('utf-8')\n",
"print(gauss[:gauss.index('\\n\\r')])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\ufeffThe Project Gutenberg EBook of Gauss, by Friedrich August Theodor Winnecke\r\n"
]
}
],
"prompt_number": 25
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"with urlopen(\"http://www.gutenberg.org/files/25447/25447-0.txt\") as f:\n",
" russell = f.read().decode('utf-8')\n",
"print(russell[:russell.index('\\n\\r')])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\ufeffProject Gutenberg's Mysticism and Logic and Other Essays, by Bertrand Russell\r\n"
]
}
],
"prompt_number": 26
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"with urlopen(\"http://www.gutenberg.org/files/42743/42743-0.txt\") as f:\n",
" table_ronde = f.read().decode('utf-8')\n",
"print(table_ronde[:table_ronde.index('\\n\\r')])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\ufeffProject Gutenberg's Les Romans de la Table Ronde (1 / 5), by Anonyme\r\n"
]
}
],
"prompt_number": 27
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"with urlopen(\"http://www.gutenberg.org/cache/epub/97/pg97.txt\") as f:\n",
" flatland_book = f.read().decode('utf-8')\n",
"print(flatland_book[:flatland_book.index('\\n\\r')])"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"\ufeffThe Project Gutenberg EBook of Flatland, by Edwin A. Abbott\r\n"
]
}
],
"prompt_number": 28
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"print(\"self\",compression_ratio(flatland_book, flatland_book))\n",
"print(\"en\",compression_ratio(flatland_book, russell))\n",
"print(\"de\",compression_ratio(flatland_book, gauss))\n",
"print(\"fr\",compression_ratio(flatland_book, table_ronde))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"self 0.6564487342348225\n",
"en"
]
},
{
"output_type": "stream",
"stream": "stdout",
"text": [
" 0.6600341125397221\n",
"de"
]
},
{
"output_type": "stream",
"stream": "stdout",
"text": [
" 0.6740207814752815\n",
"fr"
]
},
{
"output_type": "stream",
"stream": "stdout",
"text": [
" 0.6887171389789191\n"
]
}
],
"prompt_number": 29
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here is the Huffman tree for \"Flatland\", with some minor modifications to the text to make the tree more clear:\n",
"\n",
"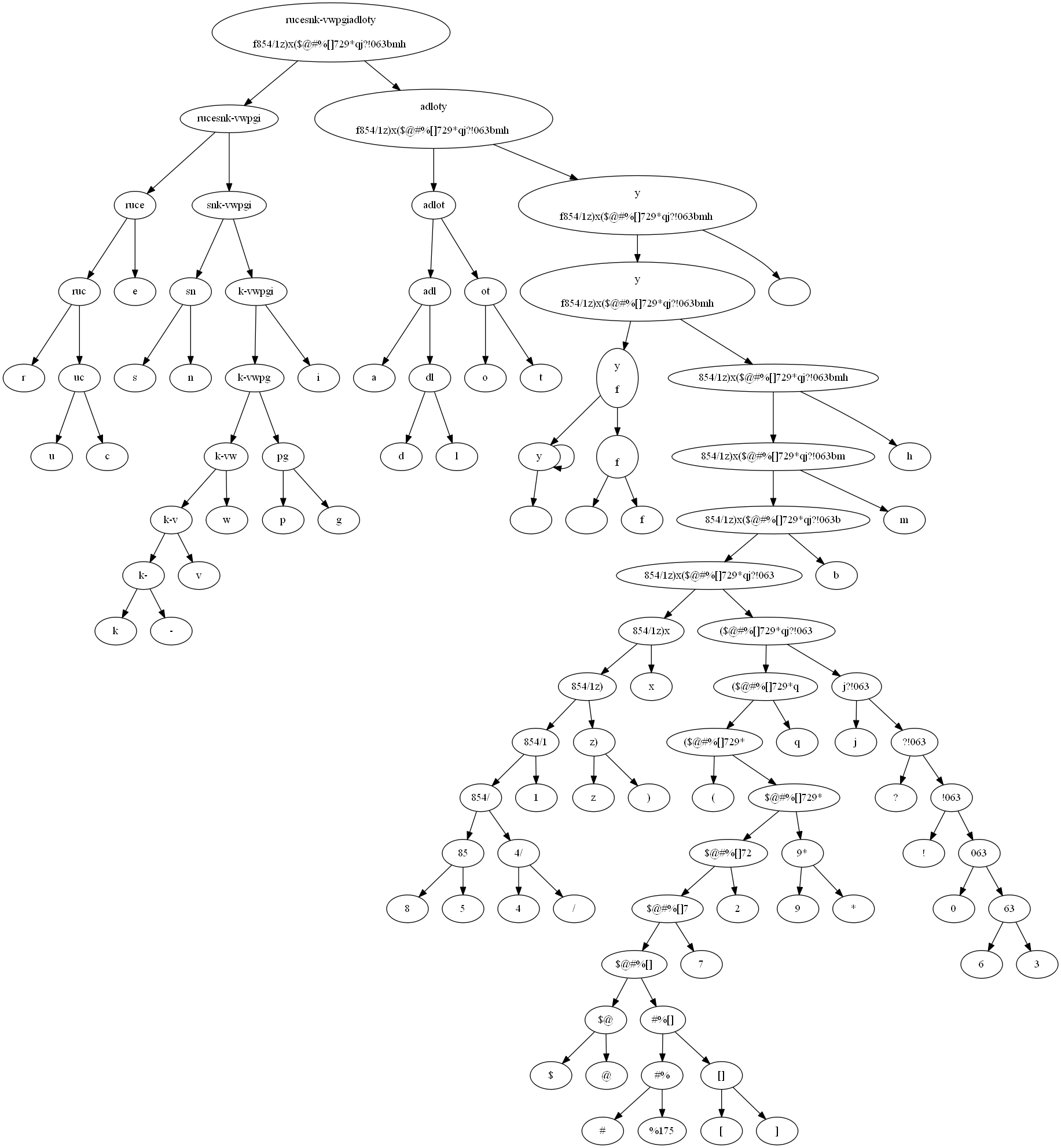"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Supplementry\n",
"\n",
"The following code was used to generate the Huffman tree image:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"import pydot # https://github.com/nlhepler/pydot-py3, http://pyparsing.wikispaces.com/Download+and+Installation"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"Couldn't import dot_parser, loading of dot files will not be possible.\n"
]
}
],
"prompt_number": 30
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def tree_to_str(tree):\n",
" if isinstance(tree, str):\n",
" return tree\n",
" return ''.join([tree_to_str(item) for item in tree])"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 31
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def add_to_node(tree, node, graph):\n",
" left, right = tree\n",
" left_node, right_node = pydot.Node(tree_to_str(left)), pydot.Node(tree_to_str(right))\n",
" graph.add_node(left_node)\n",
" graph.add_node(right_node)\n",
" graph.add_edge(pydot.Edge(node, left_node))\n",
" graph.add_edge(pydot.Edge(node, right_node))\n",
" if not isinstance(left, str):\n",
" add_to_node(left, left_node, graph)\n",
" if not isinstance(right, str):\n",
" add_to_node(right, right_node, graph)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 32
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"def tree_to_graph(tree):\n",
" graph = pydot.Dot(graph_type='digraph',strict=True)\n",
" root = pydot.Node(tree_to_str(tree))\n",
" graph.add_node(root)\n",
" add_to_node(tree, root, graph)\n",
" return graph"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 33
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"tree_to_str(tree)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 34,
"text": [
"'livadnt e'"
]
}
],
"prompt_number": 34
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"graph = tree_to_graph(tree)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 71
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"with open(\"tmp.dot\",\"w\") as f:\n",
" f.write(graph.to_string())\n",
"!dot tmp.dot -Tpng -ohuffman_tree.png \n",
"!huffman_tree.png"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 72
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"for c in flatland_book:\n",
" if ord(c) >= 128:\n",
" print(ord(c))"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "stream",
"stream": "stdout",
"text": [
"65279\n"
]
}
],
"prompt_number": 35
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"flatland_book_clean = flatland_book.replace(chr(65279), '').replace('\"','').replace(\"'\",'').replace(\",\",'').replace(\";\",'').replace(\":\",'').replace(\".\",'')\n",
"flatland_tree = build_huffman_tree(char_count(flatland_book_clean.lower()))\n",
"tree_to_str(flatland_tree)"
],
"language": "python",
"metadata": {},
"outputs": [
{
"output_type": "pyout",
"prompt_number": 38,
"text": [
"'rucesnk-vwpgiadloty\\n\\rf854/1z)x($@#%[]729*qj?!063bmh '"
]
}
],
"prompt_number": 38
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"graph = tree_to_graph(flatland_tree)"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 39
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"with open(\"tmp.dot\",\"w\") as f:\n",
" f.write(graph.to_string())\n",
"!dot tmp.dot -Tpng -oflatland_tree.png \n",
"!flatland_tree.png"
],
"language": "python",
"metadata": {},
"outputs": [],
"prompt_number": 44
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Fin\n",
"This notebook is part of the [Extended introduction to computer science](http://tau-cs1001-py.wikidot.com/) course at Tel-Aviv University.\n",
"\n",
"The notebook was written using Python 3.2 and IPython 0.13.1.\n",
"\n",
"The code is available at <https://raw.github.com/yoavram/CS1001.py/master/recitation11.ipynb>.\n",
"\n",
"The notebook can be viewed online at <http://nbviewer.ipython.org/urls/raw.github.com/yoavram/CS1001.py/master/recitation11.ipynb>.\n",
"\n",
"This work is licensed under a [Creative Commons Attribution-ShareAlike 3.0 Unported License](http://creativecommons.org/licenses/by-sa/3.0/)."
]
}
],
"metadata": {}
}
]
}